Science is broken
Hanno Böck
https://betterscience.org/
Can we trust the scientific method?
A simple example

|

|
.jpg){kind=link}
Let's do a study!
We'll do a randomized controlled trial (RCT), which is the gold standard in many fields of science.
Do Malachite crystals prevent malware infections?
Study design (RCT, part 1)
- Take a group of 20 computer users.
- Split them randomly in two groups.
Study design (RCT, part 2)
- Give one group a malachite crystal to put on their desk.
- Give the other group a fake malachite crystal that cannot be easily distinguished from a real one (control group).
- After 6 months check how many malware infections they had.
Simulate study with random data
#!/usr/bin/env python3
import os
import numpy
from scipy import stats
a = [float(os.urandom(1)[0] % 4) for _ in range(10)]
b = [float(os.urandom(1)[0] % 4) for _ in range(10)]
print("%s\n%s" % (a, b))
t, p = stats.ttest_ind(a, b)
print("%.2f;%.2f;%.2f" % (numpy.mean(a), numpy.mean(b), p))
p-value
A p-value is the probability that you get a false positive result in idealized conditions if there is no real effect.
In many fields of science p<0.05 is considered significant.
| Malachite | Fake | p-value |
|---|---|---|
| 1.40 | 1.50 | 0.87 |
| 2.10 | 1.70 | 0.40 |
| 1.50 | 1.10 | 0.44 |
| 2.10 | 1.30 | 0.12 |
| 1.10 | 1.90 | 0.11 |
| 1.20 | 1.20 | 1.00 |
| 1.80 | 2.40 | 0.12 |
| 1.70 | 2.00 | 0.58 |
| 1.20 | 1.70 | 0.30 |
| 2.10 | 1.20 | 0.06 |
| Malachite | Fake | p-value |
|---|---|---|
| 1.60 | 1.60 | 1.00 |
| 1.80 | 1.80 | 1.00 |
| 1.30 | 1.50 | 0.72 |
| 1.70 | 1.10 | 0.25 |
| 1.40 | 1.70 | 0.49 |
| 1.70 | 1.60 | 0.83 |
| 1.80 | 0.80 | 0.03 |
| 1.60 | 1.30 | 0.61 |
| 0.80 | 1.30 | 0.30 |
| 1.00 | 1.60 | 0.28 |
| Malachite | Fake | p-value |
|---|---|---|
| 1.40 | 1.50 | 0.87 |
| 2.10 | 1.70 | 0.40 |
| 1.50 | 1.10 | 0.44 |
| 2.10 | 1.30 | 0.12 |
| 1.10 | 1.90 | 0.11 |
| 1.20 | 1.20 | 1.00 |
| 1.80 | 2.40 | 0.12 |
| 1.70 | 2.00 | 0.58 |
| 1.20 | 1.70 | 0.30 |
| 2.10 | 1.20 | 0.06 |
| Malachite | Fake | p-value |
|---|---|---|
| 1.60 | 1.60 | 1.00 |
| 1.80 | 1.80 | 1.00 |
| 1.30 | 1.50 | 0.72 |
| 1.70 | 1.10 | 0.25 |
| 1.40 | 1.70 | 0.49 |
| 1.70 | 1.60 | 0.83 |
| 1.80 | 0.80 | 0.03 |
| 1.60 | 1.30 | 0.61 |
| 0.80 | 1.30 | 0.30 |
| 1.00 | 1.60 | 0.28 |

We just created a significant result out of random data
Publication Bias
What is stopping scientists from doing this?
Usually nothing!
Let's look at a real example: SSRIs (Antidepressants)
Publication Bias and Antidepressants
- 74 studies on SSRIs, data from the FDA.
- 37 out of 38 studies with positive results published.
- 14 out of 36 studies with negative results published, of those 11 claimed a positive outcome.
With Publication Bias you can create results out of nothing.
But it's not efficient, you need 20 studies on average to get a result.
How to interpret our results?
In a scientific study many decisions have to be made:
- What to do with dropouts?
- What to do with cornercase results?
- What exact outcome are we looking for?
- What variables do we control for?
Each of these decisions has a small impact on the result
p-Hacking
Even if there is no real result one of these variations may cause enough skew to be significant.
This may be a subconscious process
- Scientists don't start and say: "Today I'm gonna p-hack my result."
- They may subconsciously favor decisions that look like they may lead to the result they expect.
What stops scientists from p-Hacking?
Usually nothing.
Conclusion
The scientific method is a way to create evidence for whatever theory you like.


{kind=link}

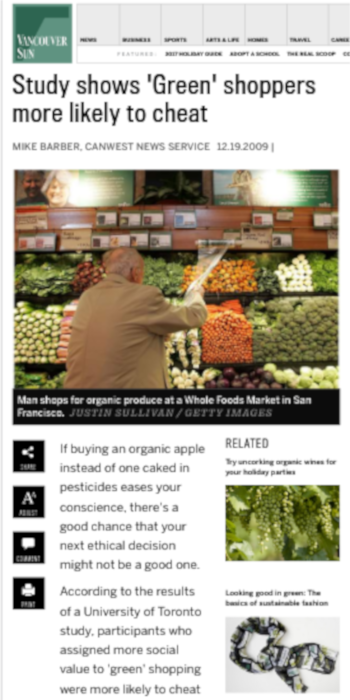
A lot of things were wrong with this study.
But it was absolutely in line with the existing standards in experimental psychology.
Psychology is facing a Replication Crisis
Many effects of psychology that were considered facts failed to replicate.



A warning
Don't be too snarky about psychologists. Your field is probably not any better. You just don't know yet.
Other fields have a replication crisis as well
Pharma company Amgen failed to replicate 47 out of 53 preclinical cancer studies in 2012.
(Though there are a few problems with this result.)
Some fields don't have a replication problem - because nobody is trying to replicate results.
What can be done about all this?
The scientific process from analysis to publication needs to be decoupled from its results.
Preregistration
Preregistration
Announce in a public registry what you plan to do in your research.
Later people can check if you published your results and if you changed your research on the way.
This is typically done in drug trials.
It doesn't work very well - but it's better than nothing.

We know Big Pharma is bad
But think about this: Whenever you read about problems in drug trials you should consider that most other fields don't do preregistration at all.
Right now there's a trend that people from computer science want to change medicine (Big Data / ML).
Some people in medicine are very worried about this - because the computer science people bring their weak scientific standards with them.
Registered Reports
Registered Reports
Turn scientific publication process upside down.
- First publish a protocol for your experiment to a scientific journal.
- Journal decides on publication based on the protocol before the results are in.
- Publish results - independent of outcome.
Other improvements
- Sharing of data, code, methods.
- Large-scale collaboration (one well-designed large study is better than many small ones).
- Higher statistical threshold (p<0.05 means practically nothing).
How's my field doing?
- Are statistical results preregistered in any way?
- Are negative results usually published?
- Are there independent replications of all relevant results?
If you answer all these questions with "No" you are probably not doing science.
You're the alchemists of our time.
Bad incentives
- Citation counts (Impact Factor).
- Publicity.
Existing incentives strongly favor interesting results - not correct results
Isn't science self-correcting?
If you confront scientists with evidence for Publication Bias and p-hacking - surely they'll immediately change their practices. That's what scientists do, right?
1959
If science is self-correcting it's pretty damn slow in doing so.
Are you prepared for boring science?
There is a choice between TED-talk science and boring science.
TED-talk science
- Mostly positive and surprising results.
- Large effects.
- Many citations.
- Media attention.
- You may be able to give a TED talk about it.
- Usually not true.
Boring science
- Mostly negative results.
- Small effects.
- Boring.
- Closer to the truth.
I prefer boring science.
But this is a tough sell.
Thanks for listening!
https://betterscience.org/https://hboeck.de/